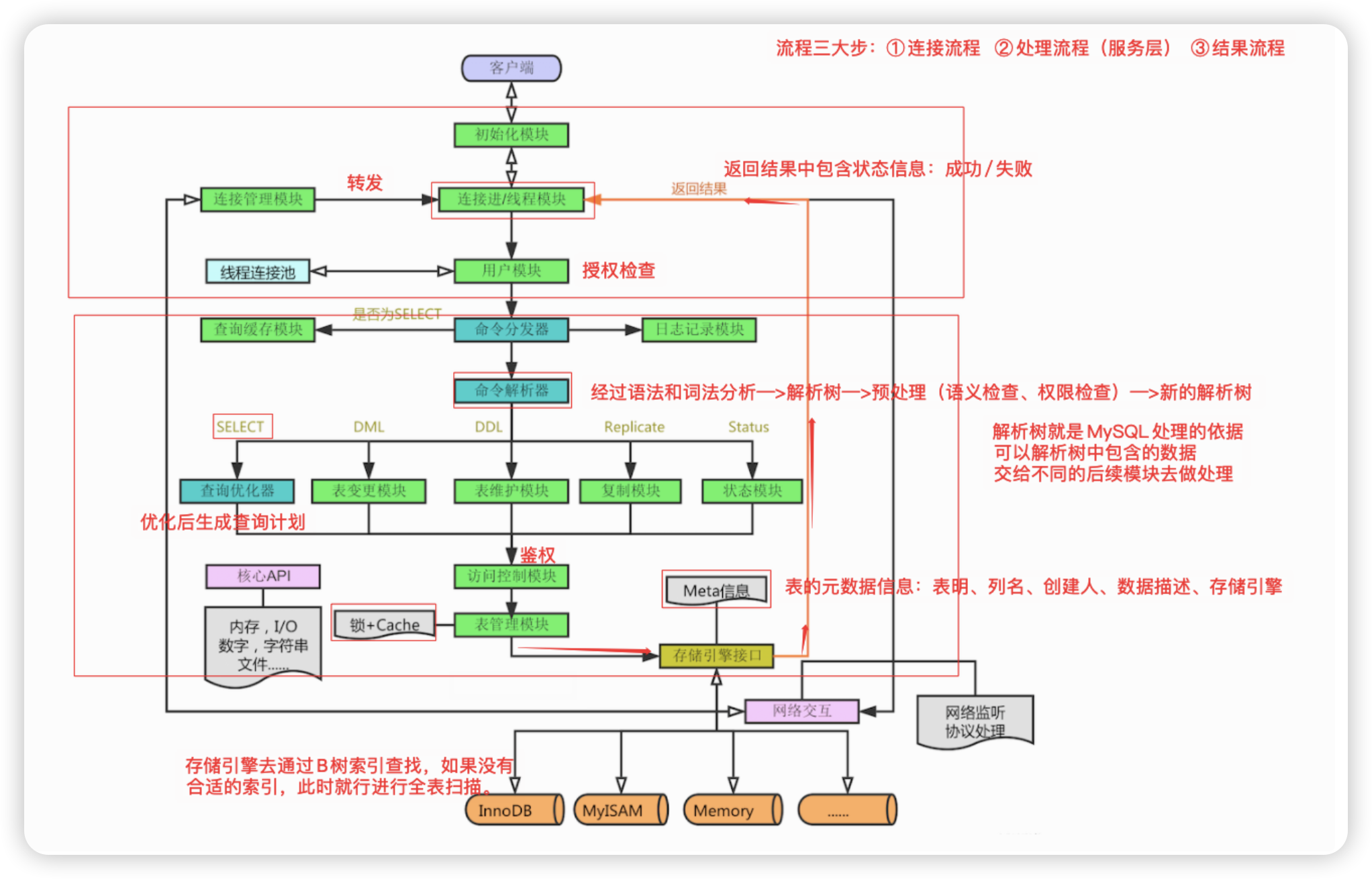
1.体系架构#
Mysql架构描述了Mysql系统的不同组件如何相互关联。Mysql架构基本上是一个客户端-服务器系统(C/S)。连接到Mysql服务器的程序是客户端,Mysql架构组要包含途中所示5个组要组件。
1.1 连接层:#
Mysql的最上层是连接服务,引入了线程池的概念,允许多个客户端连接。主要工作是负责:连接处理、认证授权、安全防护、管理连接等。
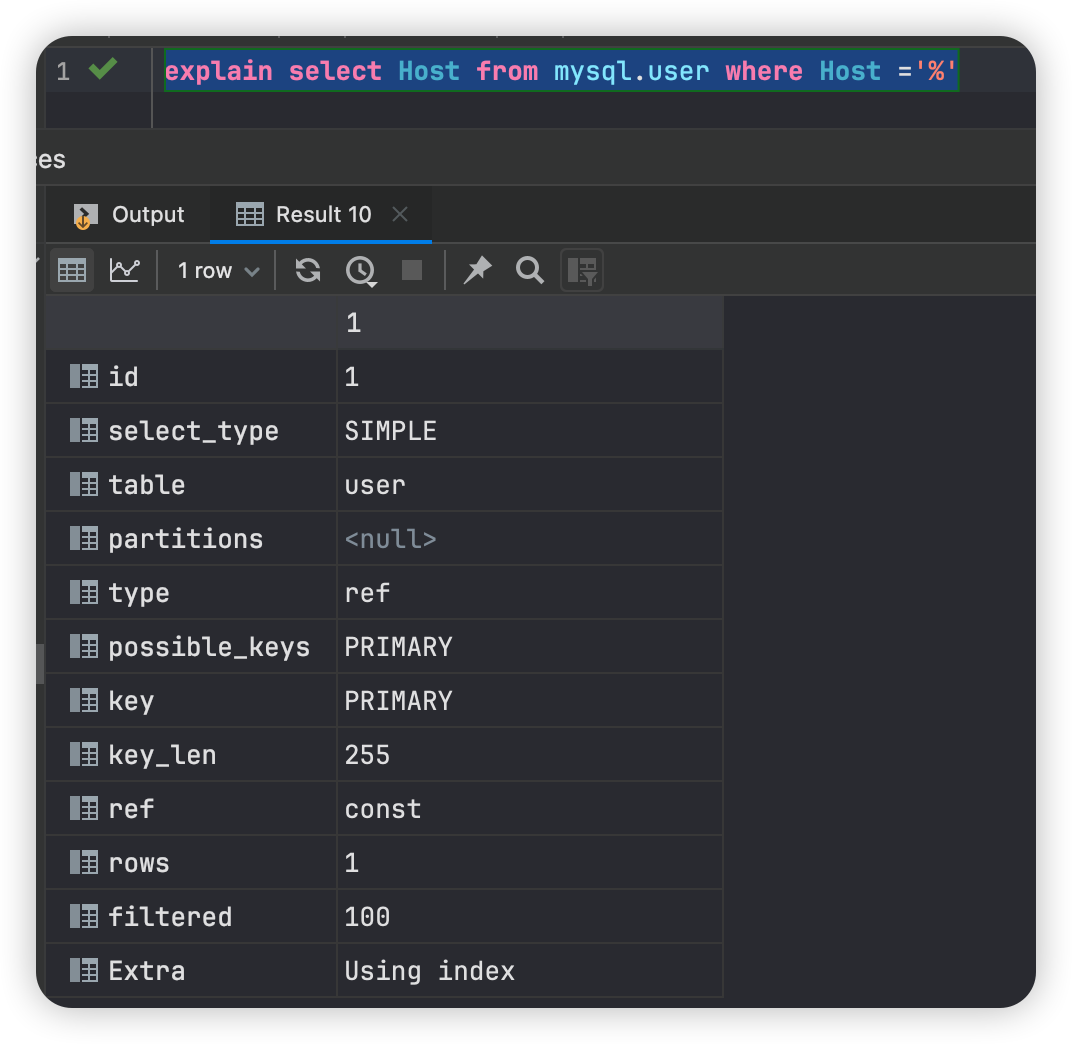
当客户端连接到Mysql服务器时,服务器会对其进行认证。基于用户名、主机、密码信息在user表中根据host、user、authentication_string三个字段判断当前客户端是否允许登录。
一旦客户端连接成功,想要执行具体的sql时,连接层便会继续检查该客户端的相关权限,在进行权限校验时,Mysql首先检查user表,如果执行sql需要的权限没有在user表中被授予,那么会继续向下检查db表,db表是下一安全层级,db表所指向的权限限定在数据库层级,在该层级如果没有找到限定需要的权限,Mysql则会继续向下查找tables_priv表以及colums_priv表,如果所有表都查找完任然没有指定需要的权限,此时Mysql将会返回错误信息。
Mysql通过向下层级的顺序(user—>db—>tables_priv—>colums_priv)检查权限,一旦找到执行本次sql需要的权限后就会结束
连接层为通过安全认证的接入客户端提供线程,同样的,在该层上可以实现基于SSL的安全连接。连接层还负责Mysql服务器与客户端的通信,接受客户端的请求,返回server端的执行结果等。
查看当前server端的链接情况以及最大连接数:
show full processlist;
show variables like 'max_connection%';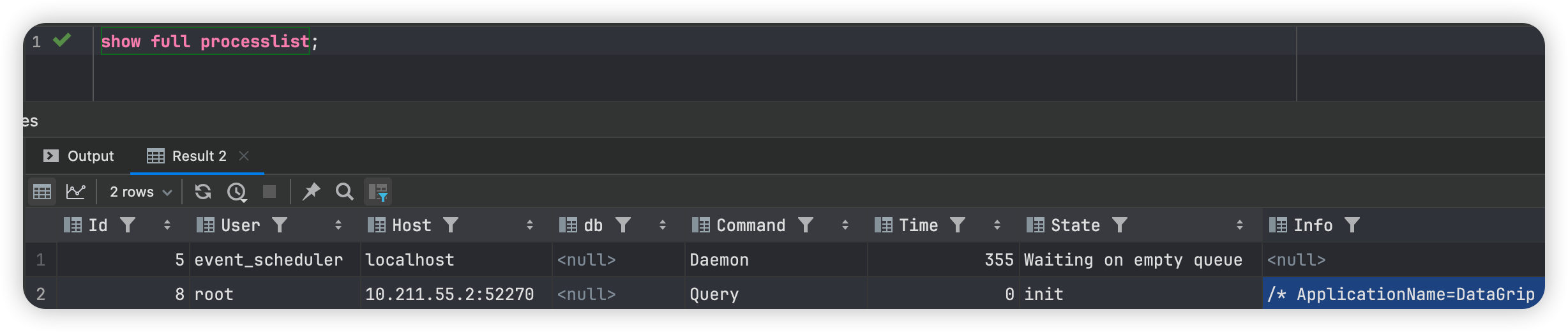
1.2 服务层:#
服务层用于处理核心服务,如标准SQL接口、NoSQL接口、查询解析、SQL优化和统计等。
所有与存储引擎无关的工作也在服务层完成,例如:存储过程、函数、触发器、视图等。
在该层,服务器会解析查询sql并创建相应的内部解析树,并完成对其的优化,最后生成相关的执行操作。
如果是select语句,服务器还会查询内部的缓存,以此来提高查询的性能,该功能在Mysql8中已经移除,原因主要是缓存命中条件太苛刻,命中率太低。
服务层组件主要包括以下:
-
系统管理和实用程序:包括备份恢复、安全管理、集群管理服务和工具。 -
SQL接口:接收客户端发送的各种SQL语句,比如:存储过程、DDL、DML等,并且返回执行结果。
-
缓存(Cache && Buffer):主要是将查询的语句和查询结果缓存起来,由于已经移除,不做过多讨论。
-
SQL解析器(Parser):如果没有命中查询缓存,SQL语句就会传递到解析器进行解析和验证,主要是进行此法解析和语法解析,比如sql语句错误就是在该层返回的错误结果。
-
词法解析:
需要识别出SQL语句中的各个字符串分别是什么,代表什么
通过识别到的SELECT关键字可以知道是一个查询语句
-
语法解析:
根据SQL的语法规则,判断输入的SQL语句是否满足要求,比如检查表是否存在,列是否存在等等
将SQL语句进行语义解析和语法解析,分解成数据结构(解析树),然后按照不同的操作类型进行分类,后续的SQL语句传递和处理都是基于这棵生成的解析树

-
-
查询优化器(Optimizer):拿到解析树之后并不会立即调用存储引擎来执行sql,而是会在这一层对SQL进行优化,优化器是一个复杂的部件,它会帮助我们以它认为最优的方式去执行这条SQL语句,并生成一条一条的执行计划。优化器会对SQL语句进行一些简单的处理。具体就不举例了。
-
执行器:执行器的工作内容就是:调用存储引擎层的接口执行SQL语句或者其他操作,将存储引擎的执行结果向上返回给客户端,SQL语句执行完成
整个过程:
- 解析器知道你要干什么(select 还是update、或者insert)
- 优化器知道怎么做最合适
- 执行器最终去执行
1.3 存储引擎层#
存储引擎负责Mysql中数据的读取和写入,sql语句的执行是通过服务层的执行器调用存储引擎层的API来完成的,通过接口屏蔽了不同存储引擎之间的差异
这里聊一下InnoDB和MyISAM2中最常用的存储引擎在文件目录的存储上的差异:
InnoDB#
-
表结构:为了保存表结构,InnoDB在数据目录下对应的数据目录下专门创建一个后缀为frm的文件用来描述表的结构 -
表中的数据和索引:系统表空间:默认情况下,InnoDB会在数据目录下创建一个名为ibdata1、大小为12M的文件,这个文件就是对应的系统表空间在filesystem上的表示,这个文件是自扩展文件,大小不够时会自动增加文件大小独立表空间:在mysql5.6版本之后,InnoDB并不会默认把各个表的数据存储到系统表空间,而是为每一个表建立一个独立表空间,也就是说,有多少张表就有多少个独立表空间。使用独立表空间存储数据时,会在对应数据库目录中创建一个表示该独立表空间的文件,文件名和表明相同,后缀为ibd,而在mysql8之后,进一步整合将frm和ibd文件进一步整合,把表的结构描述信息页添加到了ibd文件中

我们可以自己指定是使用系统表空间还是独立表空间来存储数据,该功能由参数innodb_file_per_table控制
[server]
innodb_file_per_table=0 # 0:代表使用系统表空间; 1:代表使用独立表空间MyISAM#
- 表结构:和InnoDB一样,也是在数据目录下创建一个专门描述表结构的frm文件
- 表中的数据和索引:由于该存储引擎的数据和索引是分开存储的(非聚集索引),所以在文件系统中也是使用不同文件来存储数据和索引
test.frm 存储表结构
test.MYD 存储数据 (MYData)
test.MYI 存储索引 (MYIndex)举例:数据库A、表B
1、如果表采用InnoDB存储引擎,数据目录的文件夹A中会产生1个或者2个文件
- B.frm:描述表的结构,字段长度等
- 如果采用系统表空间:数据和索引都存储在数据目录下的ibdata1文件中
- 如果采用独立表空间:A文件夹中除了B.frm文件,还会存在一个B.ibd文件
mysql5.7会在数据目录下具体数据库文件夹下创建db.opt文件,用于保存数据库相关配置。比如:字符集、比较规则。而Mysql8不再提供。
Mysql8不再提供frm文件,而是合并到ibd文件中
2、如果表采用MyISAM存储引擎,会在A文件夹下产生3个文件
- B.frm:描述表的结构,字段长度等
- 在8.0中为 B.xxx.sdi
- B.MYD:数据信息文件,存储数据信息(独立表空间模式)
- B.MYI:索引文件
1.4 物理存储层#
存储引擎的下层是最后的物理存储层(磁盘)。包括:binlog日志、数据文件、错误日志、查询统计、redo/undo 日志、慢查询日志等等。
2 SQL运行机制#
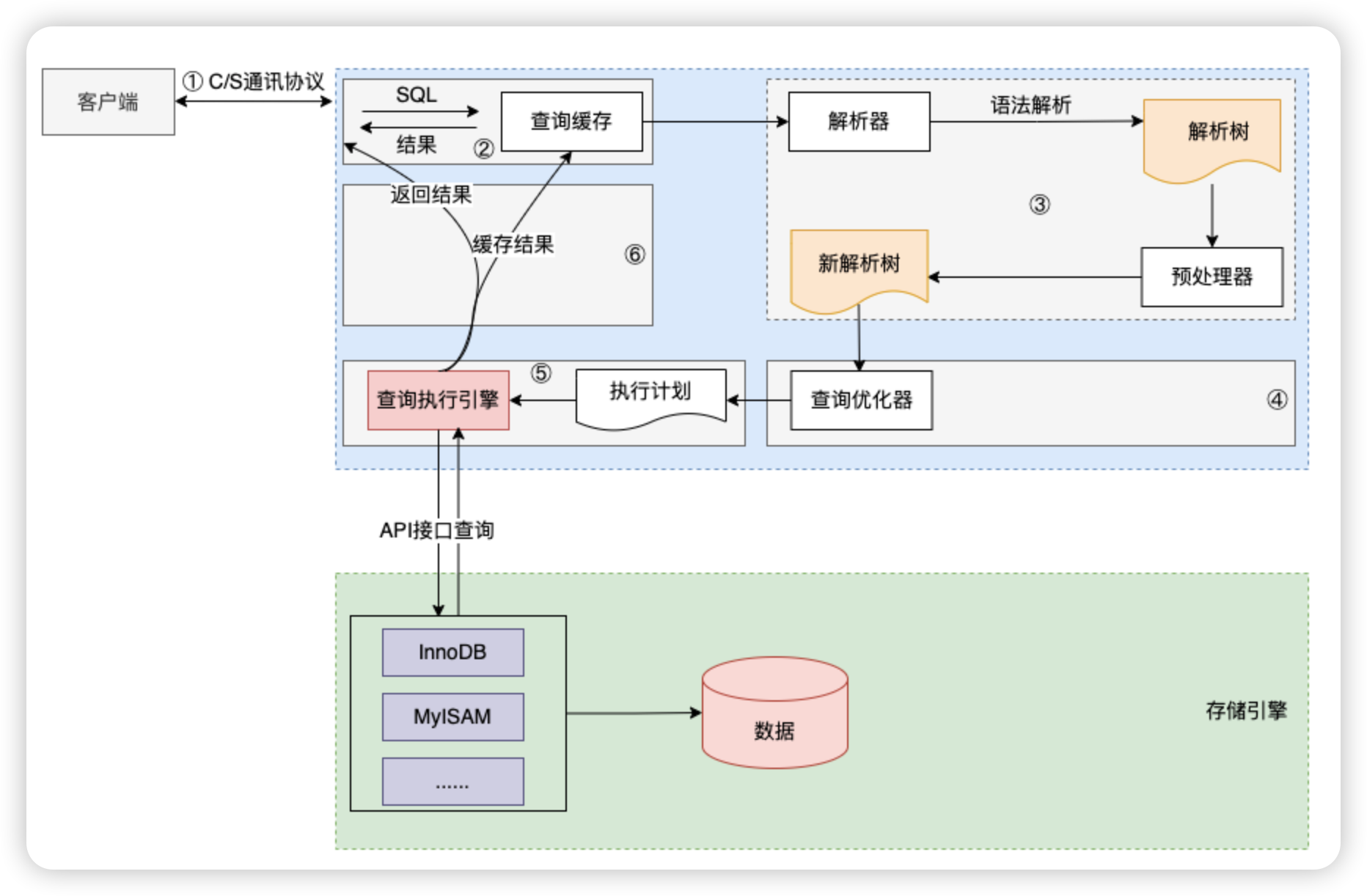
流程描述:
①:通过客户端/服务器通信协议与Mysql建立连接。
②:查询缓存:如果开启了查询缓存,并且能够在查询缓存中找命中到完全相同的SQL语句,则将缓存的查询结果直接返回到客户端,否则SQL语句会由解析器经过词法和语法解析生成解析树。
③:预处理器进行权限检查生成新的解析树
④:查询优化器针对语法树生成执行计划
⑤:执行器调用存储引擎接口,执行sql,得到执行结果
⑥:有Mysql Server过滤后并缓存后将执行结果返回给客户端
2.1 C/S 通信协议#
建立连接,Mysql客户端与服务端的通信方式是”半双工“,对于每一个连接,时刻都有一个线程来标记这个连接正在干什么
通讯机制:
全双工:任意时刻,客户端与服务端既可以发送数据也可以接收数据
半双工:任一时刻,要么是客户端向服务端发送数据,要么是服务端向客户端发送数据,这2个动作不能同事发生
半双工:一旦一端开始发送消息,了;另一端需要接受完整的消息后才能进行相应,无法将消息切分成多个小块独立发送,也无法进行流量控制
客户端用一个单独的数据包将查询语句发送给服务端,如果查询语句很长的时候需要调整max_allowed_packet参数默认是64M

2.2 查询缓存#
由于在8.0该组件已删除,不做额外讨论
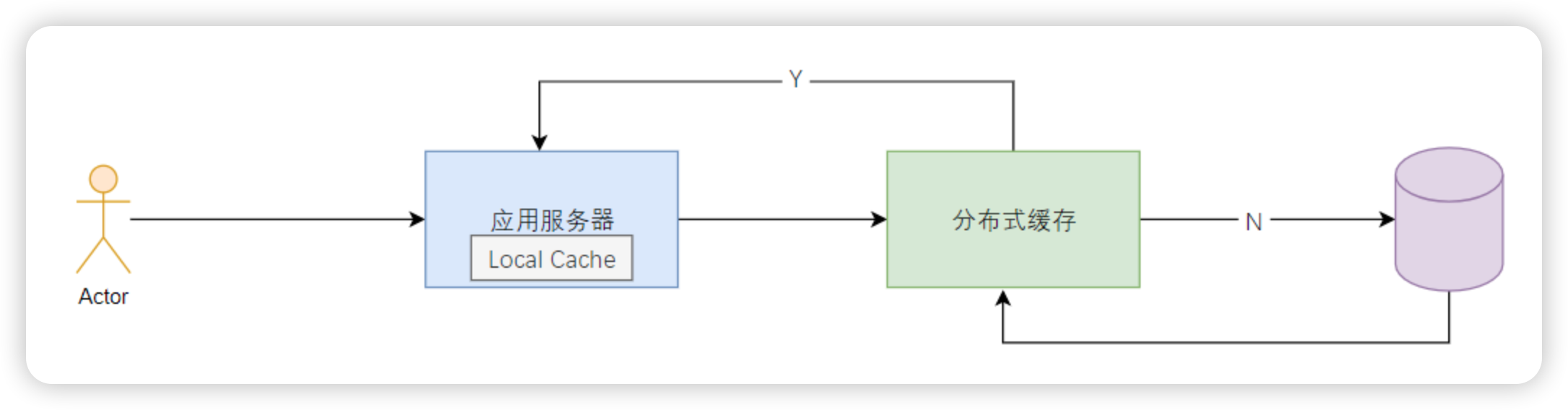
通常情况下也不会使用Mysql服务端的查询缓存,而是使用专门的缓存中间件来作为缓存组件,看情况考虑是否采用多级缓存
2.3 语法解析和预处理#
Mysql通过关键字将SQL语句进行解析,并生成一颗对应的解析树。这个过程主要通过语法规则来验证和解析,比如SQL语句中是否使用了错误的关键词或者关键字的顺序是否正确等。预处理则会根据规则进一步检查解析树是否合法。比如需要检查查询的数据库和表以及查询的列是否存在等。

2.4 查询优化器#
根据解析树生成最优的执行计划

① 逻辑优化:
对SQL语句做一些等价交换、对条件表达式进行等价谓词重写、条件顺序调整、条件简化、视图重写、子查询/连接查询优化。
② 物理优化:
CBO:Cost-Based Optimizer,基于代价的优化,根据模型计算出各个执行计划的代价,选择代价最小的一个
RBO:Rule-Based Optimizer,主要根据预制的规则对查询进行优化
2.5 执行引擎#
负责调用对应的存储引擎执行sql语句,根据sql语句中表的存储引擎类型,以及对应的API接口与下层的存储引擎的交互,得到查询结果并返回
如果查询结果过多,采用增量模式返回
2.6 流程总结#